

Up to now few weeks, a number of “autonomous background coding brokers” have been launched.
- Supervised coding brokers: Interactive chat brokers which might be pushed and steered by a developer. Create code regionally, within the IDE. Software examples: GitHub Copilot, Windsurf, Cursor, Cline, Roo Code, Claude Code, Aider, Goose, …
- Autonomous background coding brokers: Headless brokers that you just ship off to work autonomously by way of an entire process. Code will get created in an setting spun up solely for that agent, and normally ends in a pull request. A few of them are also runnable regionally although. Software examples: OpenAI Codex, Google Jules, Cursor background brokers, Devin, …
I gave a process to OpenAI Codex and another brokers to see what I can be taught. The next is a document of 1 specific Codex run, that can assist you look behind the scenes and draw your individual conclusions, adopted by a few of my very own observations.
The duty
We’ve got an inner utility referred to as Haiven that we use as a demo frontend for our software program supply immediate library, and to run some experiments with totally different AI help experiences on software program groups. The code for that utility is public.
The duty I gave to Codex was relating to the next UI challenge:
Precise:

What I needed from the agent:

Immediate: After we create the filter labels on the dashboard, we create human readable labels based mostly on the classes we now have. "client-research" is became "Consumer-Analysis", "deliveryManagement" into "DeliveryManagement". Enhance the sophistication of the "category-to-human-readable" logic in order that the labels are showing to the consumer as "Consumer Analysis" and "Supply Administration"
This process is
- Comparatively small
- A typical “cosmetics” process that’s not tremendous pressing and may get deprioritised many times
Agent logs
I’m sharing the detailed logs right here to be able to get an impression of what’s going on beneath the hood.
Right here’s what the logs view seems like in Codex:
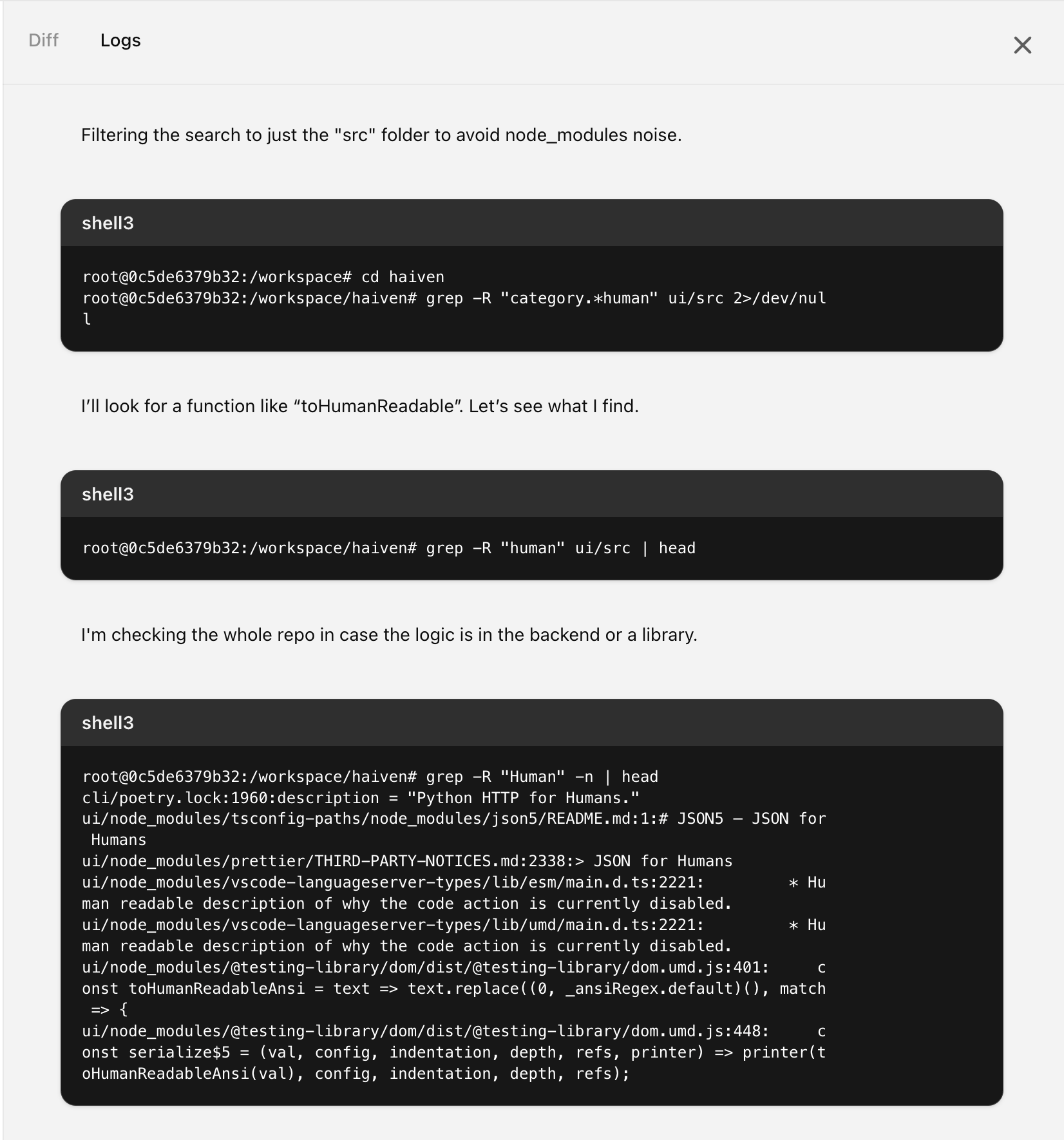
Accumulating info first
The primary 17 log entries had been all about studying AGENTS.md and README.md:
- “I must test the AGENTS.md within the repository root for directions.”
- seems for AGENTS.md, however I had truly referred to as it AGENT.md, which led to some backwards and forwards till it figured that out
- reads README.md
- Appears to be like at .pre-commit, finds a take a look at setup
The next tables checklist the remainder of the log messages verbatim. After every of these messages, the agent executed a command, for a few of them I added that precise command for context. I’m positive that the log messages are simply summaries of the tokens that had been truly happening behind the scenes, as a result of the messages are approach too brief to characterize the complete “considering” the mannequin will need to have been going by way of.
Looking for the related code with plenty of grep
| Message | Command (samples) | Notes |
|---|---|---|
| I must seek for “category-to-human-readable” to find the place to make modifications for the frontend labels. | grep -R "human readable" -n |
|
| I’ll search for any mentions of “class” within the mission. | ||
| Grep output is huge due to node_modules; I’ll restrict it to src as an alternative. | ||
| I’ll seek for “to human” within the src listing to seek out related references. | ||
| I’ll open and test index.js to see what’s inside. | ||
| I’m checking if the category-to-human-readable transformation is dealt with in _navigation_items or elsewhere. | ||
| I’m going to search for “human readable” to get extra information on the subject. | grep -R "human-readable" -n ui/src | head |
|
| I ponder if there’s a perform for changing classes into one thing extra readable. | ||
| Filtering the search to simply the “src” folder to keep away from node_modules noise. | second time it’s operating into this, didn’t ‘bear in mind’ | |
| I’ll search for a perform like “toHumanReadable”. Let’s see what I discover. | ||
| I’m checking the entire repo in case the logic is within the backend or a library. | grep -R "Human" -n | head |
|
| I’ll restrict the scope to app/ and ui/src to keep away from the big node_modules folder. | third time it’s operating into this, didn’t ‘bear in mind’ | |
| I believe the logic is likely to be lacking, so I’ll test _navigation_items and different modules for classes. | grep -R "human" app -n | head |
|
| I believe it’s time to look a bit deeper. Let’s dive in and discover. | grep -R "human" app | wc -l |
To “look deeper”, it searches for “human” once more, however pipes it into wc as an alternative of head? |
Lastly, it’s getting nearer! The labels had been beforehand crudely capitalized through CSS, it finds that
| Message | Command (samples) | Notes |
|---|---|---|
| I’m checking for references to “capitalize” or class transformation within the frontend. | Output: |
|
| I’ll test across the Tag part in index.js. | ||
| Tag show capitalizes phrases incorrectly as a result of hyphen or camelCase; I’ll take a look at filter classes. |
Now it’s beginning to test for extra related code within the app folder, the place the backend is. It doesn’t discover something, which is right, there’s nothing related there
| Message | Command (samples) | Notes |
|---|---|---|
| I’ll test the repo for a way classes are formatted, specializing in hyphens and camelCase. | grep -R "classes" -n app | head |
|
| Time to attempt a brand new search! | grep -R "shopper" -n app | head |
|
| I’ll take a better take a look at the prompts within the take a look at information. | grep -R "classes:" -n app/assessments | head |
Why? |
| It seems just like the take a look at information has restricted classes. I’ll test the docs for any variations. | grep -R "client-research" -n |
|
| I’ll begin by opening the recordsdata to take a better look. | sed -n '1,100p' ui/src/app/_navigation_items.js |
Now it’s going again to looking within the ui folder – it discovered the CSS beforehand, and is now searching for current code that it might reuse to unravel the duty. That’s nice, as a result of we certainly have already got the same perform, and it finds it:
| Message | Command (samples) | Notes |
|---|---|---|
| I would like a perform to transform tags like “client-research” to “Consumer Analysis” for filters. | grep -R "to.*Readable" -n ui/src | head |
|
| I’m opening the toReadableText perform inside _dynamic_data_renderer.js to discover it. | ||
| I’m transferring by way of the web page to get the small print I would like. |
It now finds a niche within the current perform’s implementation:
| Message | Command (samples) | Notes |
|---|---|---|
| I see that hyphens aren’t dealt with by the perform. I would like to regulate it for hyphens. | ||
| I’ll modify toReadableText to deal with hyphens, guaranteeing correct capitalization and spacing. Let’s test assessments! | It truly didn’t test any assessments | |
| I’ll test _dynamic_data_renderer.js to look at toReadableText and modify it for hyphen-case. | ||
| I’ll test assessments/_sidebar.take a look at.js to evaluate the associated classes there. | ||
| I’ll test different recordsdata to see if toReadableText seems anyplace. | ||
| I’ll test if _sidebar or others comprise a toReadableText perform. |
Replace the take a look at for the perform that it desires to alter:
| Message | Command (samples) | Notes |
|---|---|---|
| I’ll alter the perform to deal with hyphen-case, then replace assessments to replicate that. | ||
| I’ll test the take a look at file after line 36 to make sure hyphen-case is roofed. | ||
| I’ll scroll by way of strains 60 to 120 to look at the remainder of the file. | ||
| I’m scrolling the remainder to seize all of the related info. | ||
| I’ll add assessments for hyphen-case and replace toReadableText, together with modifying index.js for classes. | ||
| I’ll alter _dynamic_data_renderer.js and index.js to make use of toReadableText and replace assessments. | git standing --short |
You possibly can configure some setting startup instructions in Codex, I had configured that to be yarn set up, which led to the next:
| Message | Command (samples) | Notes |
|---|---|---|
| There are untracked .yarn/ and .yarnrc recordsdata. I’ll test and clear them up. | ||
| I’ll test the foundation of ‘ui’ and take away any pointless Yarn 4 entries. | ||
| I’ll take a look at the commit historical past to see if these .yarn recordsdata had been added later. | git log --oneline -n 1 |
|
| I’ll evaluate the repository’s .gitignore to verify if Node modules are excluded. | grep yarn .gitignore |
|
| I see no entry for .yarn or .yarnrc. I’ll test and take away them if wanted. | cat ui/.gitignore |
|
| I’ll test if I can take away .yarn or .yarnrc recordsdata since they shouldn’t be dedicated. | ||
| It seems like yarn.lock modifications had been made. Time to reset to HEAD. |
Precise code modifications:
| Message | Command (samples) | Notes |
|---|---|---|
| Time to change the code. I’ll start the mandatory updates now. | sed -n '1,30p' ... |
|
| I’m going so as to add a hyphen to the mandatory a part of the code. | ||
| I’m going to make modifications to the index.js file now. | ||
| I’ll import toReadableText and begin utilizing it within the code. | ||
| I’ll replace index.js to import toReadableText and alter the _dynamic_data_renderer assessments. | ||
| I would like to switch {tag} with {toReadableText(tag)} for higher rendering. | ||
| I’ll check out the variations to higher perceive the modifications. | git diff |
|
| I’ll evaluate the modifications in index.js to see what’s been modified. | ||
| I’ll add a brand new take a look at for hyphenated circumstances in _dynamic_data_renderer.take a look at.js. | ||
| I’ll take into account inserting a take a look at after line 35. |
Operating our code linter subsequent, good:
| Message | Command (samples) | Notes |
|---|---|---|
| I’ll format the code utilizing Prettier as instructed. | cd ui && npx prettier -w ... |
Prettier is talked about within the AGENTS.md. It appears to run prettier efficiently, although not one of the recordsdata had been modified |
| I’ll evaluate the logs to collect extra info. |
Attempting to run the assessments – unsuccessfully:
| Message | Command (samples) | Notes |
|---|---|---|
| I’ll run the yarn assessments to test if all the things’s working advantageous. | ||
| Exams may’ve been cached or want community—output’s empty, so I’ll test the log. | ||
| The lockfile isn’t up to date. I’ll attempt operating ‘yarn set up’ for the reason that setting permits it. | ||
| The setting is offline, so yarn set up can’t be run, however I see a node_modules folder. | ||
| I see node_modules are already put in. I’ll test the log for why assessments failed. | ||
| The error occurs as a result of Yarn 4 depends on .yarn and .yarnrc, which we eliminated. | ? | |
| It seems like .yarnrc.yml isn’t tracked. I’ll additionally test .yarn for monitoring. | ||
| I’m double-checking the bundle.json to see if “haiven-ui” is the right title. | ? | |
| I’ll test the Node model to verify if it’s 18 or 20 by operating node -v. | bizarre, the node model laid out in bundle.json is 22.6 | |
| I believe switching to npx vitest run might repair the error. Let’s attempt that. | ||
| The output is lengthy—now I’ll seize the final abstract strains. | Error: Not applied: window.getComputedStyle(elt, pseudoElt) |
|
| The output is just too lengthy, so I’ll extract the important thing factors for a abstract. |
Occurring a tangent about organising the venv, which is completely pointless as a result of it solely plans modifications for frontend code:
| Message | Command (samples) | Notes |
|---|---|---|
| The assessments failed as a result of case variations, however now I’ll activate the digital setting. | AGENTS.md comprises directions to activate venv for the Python backend, however we’re within the frontend right here, so… | |
| Hmm, the .venv isn’t right here. I ought to test if it wants creation or already exists. | ||
| It seems just like the .venv listing is lacking. Let’s evaluate AGENT’s directions rigorously. | ||
| The setting appears offline, however there is likely to be a script to arrange dependencies regionally. | ||
| I can’t run “poetry set up” offline, however I’ll test the .cursor folder for dependencies. | ||
| I can’t run backend assessments with the present setup, however I’ll attempt pytest anyway. |
Gave up on the assessments, now wrapping up the modifications:
| Message | Command (samples) | Notes |
|---|---|---|
| Exams failed as a result of lacking dependencies. Now, I’ll test standing and proceed with committing. | ||
| I believe the .yarnrc.yml was left over from a earlier yarn set up. Eradicating it. | ||
| I’ll seize the related file strains for the citations now. | ||
| I’ll get the encompassing line vary for the modifications in index.js. | nl -ba ui/src/pages/index.js | sed -n '12,28p' |
|
| I’ll seize the related strains round these modifications now. | ||
| It’s time to finalize the PR message and confirm the commit. | ||
| UI assessments failed as a result of setting points. I’ll reference the final failure strains. Accomplished! |
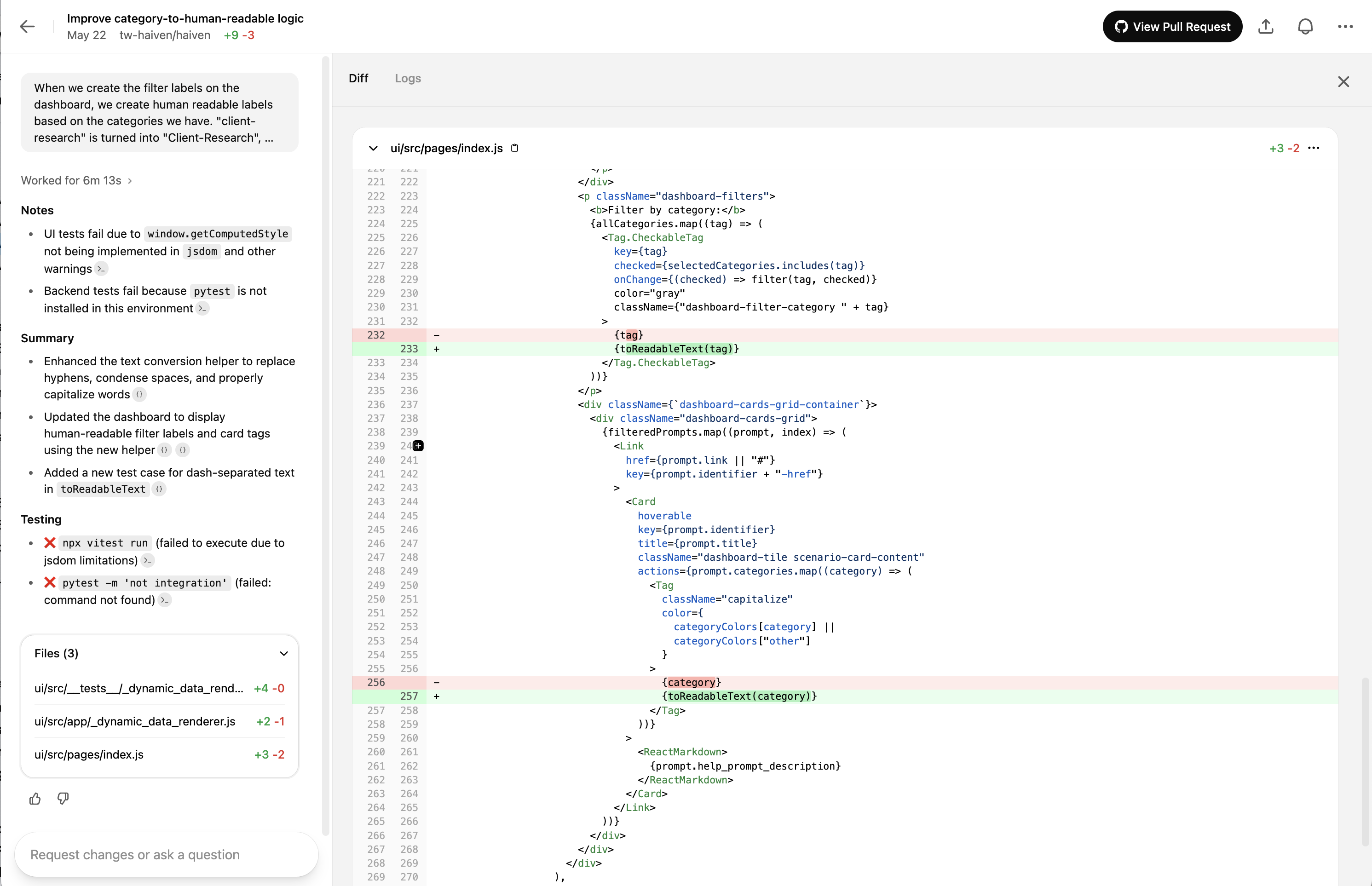
Right here is the complete pull request created by Codex.
Observations
Brute textual content search
I discovered it fascinating to see that Codex, and a lot of the different coding assistants I’m utilizing, are resorting increasingly more to easy textual content search to seek out related code. Within the log above you see how Codex goes by way of a bunch of search phrases with grep, to seek out related items of code (“human”, “human readable”, “humanReadable”, …). The rationale why I discover it fascinating is as a result of there have been a variety of seemingly extra subtle code search mechanisms applied, like semantic search over codebase indices with vectors / embeddings (Cursor, GH Copilot, Windsurf), or utilizing the summary syntax tree as a place to begin (Aider, Cline). The latter remains to be fairly easy, however doing textual content search with grep is the only potential.
It looks as if the instrument creators have discovered that this straightforward search remains to be the simplest in any case – ? Or they’re making some type of trade-off right here, between simplicity and effectiveness?
The distant dev setting is essential for these brokers to work “within the background”
Here’s a screenshot of Codex’s setting configuration display (as of finish of Might 2025). As of now, you may configure a container picture, setting variables, secrets and techniques, and a startup script. They level out that after the execution of that startup script, the setting won’t have entry to the web anymore, which might sandbox the setting and mitigate a few of the safety dangers.
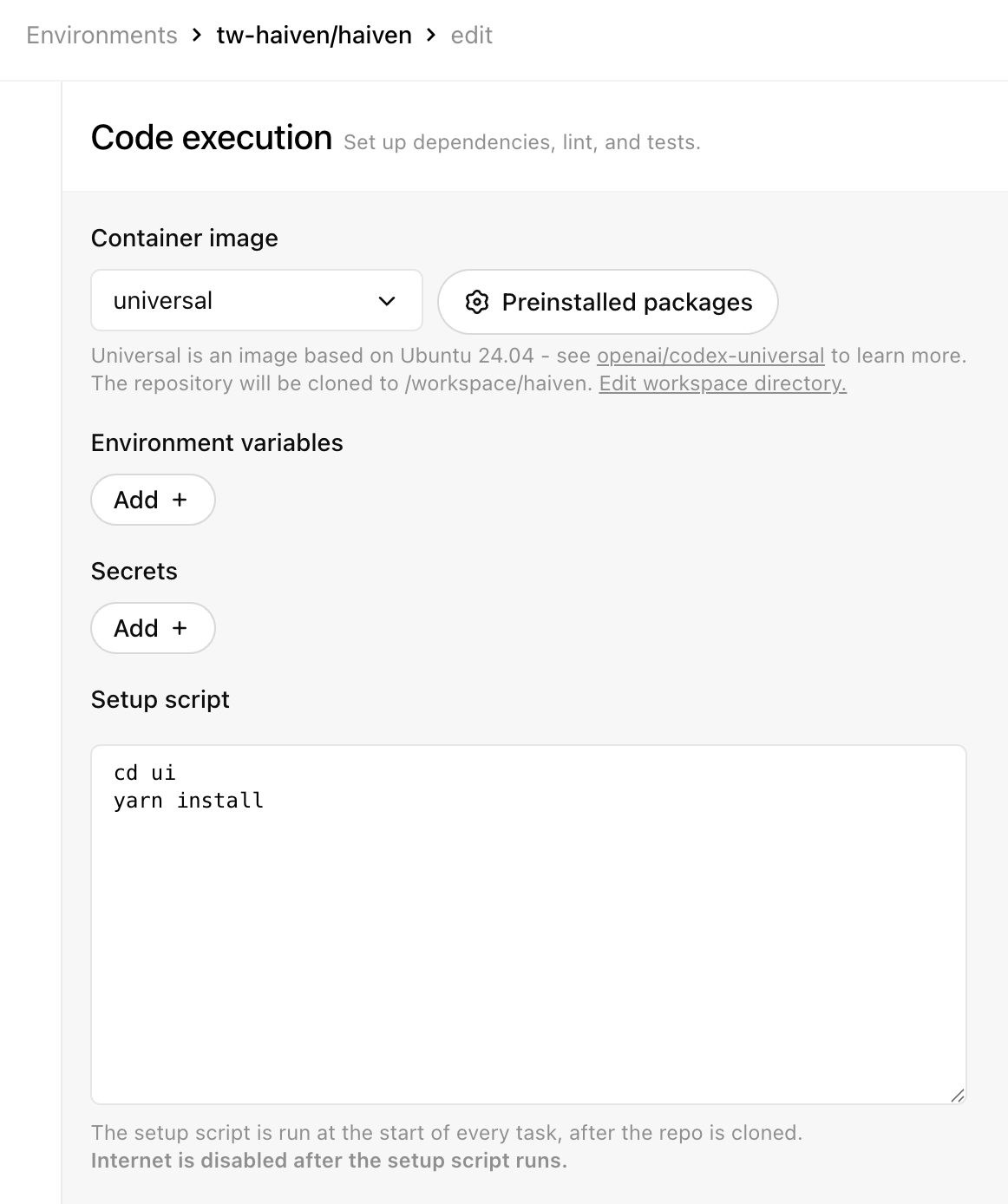
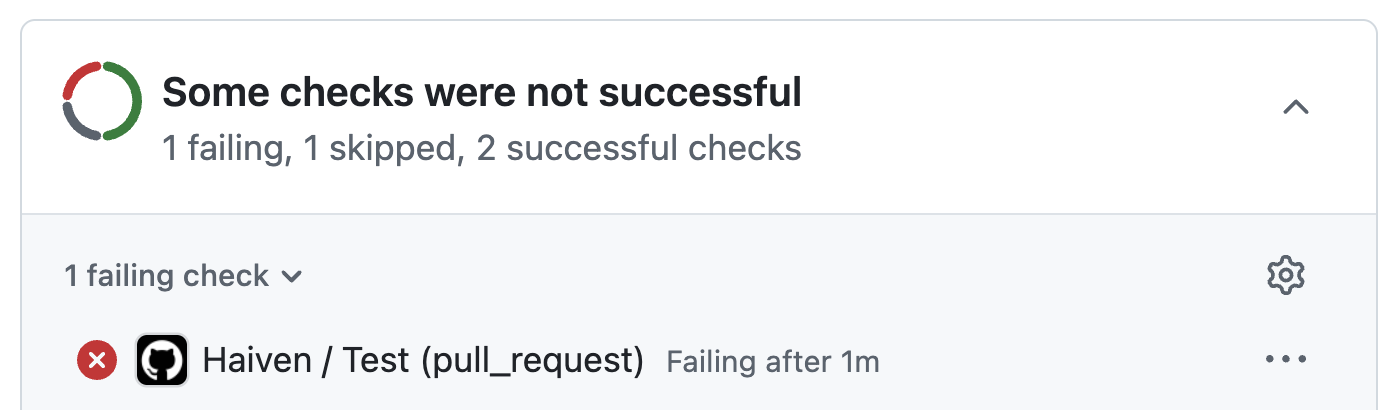
For these “autonomous background brokers”, the maturity of the distant dev setting that’s arrange for the agent is essential, and it’s a difficult problem. On this case e.g., Codex didn’t handle to run the assessments.

And it turned out that when the pull request was created, there have been certainly two assessments failing due to regression, which is a disgrace, as a result of if it had recognized, it could have simply been in a position to repair the assessments, it was a trivial repair:
This specific mission, Haiven, truly has a scripted developer security internet, within the type of a fairly elaborate .pre-commit configuration. () It could be ideally suited if the agent might execute the complete pre-commit earlier than even making a pull request. Nonetheless, to run all of the steps, it could must run
- Node and yarn (to run UI assessments and the frontend linter)
- Python and poetry (to run backend assessments)
- Semgrep (for security-related static code evaluation)
- Ruff (Python linter)
- Gitleaks (secret scanner)
…and all of these must be accessible in the best variations as nicely, after all.
Determining a clean expertise to spin up simply the best setting for an agent is essential for these agent merchandise, if you wish to actually run them “within the background” as an alternative of a developer machine. It isn’t a brand new drawback, and to an extent a solved drawback, in any case we do that in CI pipelines on a regular basis. However it’s additionally not trivial, and in the mean time my impression is that setting maturity remains to be a difficulty in most of those merchandise, and the consumer expertise to configure and take a look at the setting setups is as irritating, if no more, as it may be for CI pipelines.
Answer high quality
I ran the identical immediate 3 occasions in OpenAI Codex, 1 time in Google’s Jules, 2 occasions regionally in Claude Code (which isn’t totally autonomous although, I wanted to manually say ‘sure’ to all the things). Regardless that this was a comparatively easy process and resolution, turns on the market had been high quality variations between the outcomes.
Excellent news first, the brokers got here up with a working resolution each time (leaving breaking regression assessments apart, and to be trustworthy I didn’t truly run each single one of many options to verify). I believe this process is an effective instance of the categories and sizes of duties that GenAI brokers are already nicely positioned to work on by themselves. However there have been two facets that differed when it comes to high quality of the answer:
- Discovery of current code that may very well be reused: Within the log right here you’ll discover that Codex discovered an current element, the “dynamic information renderer”, that already had performance for turning technical keys into human readable variations. Within the 6 runs I did, solely 2 occasions did the respective agent discover this piece of code. Within the different 4, the brokers created a brand new file with a brand new perform, which led to duplicated code.
- Discovery of a further place that ought to use this logic: The staff is at the moment engaged on a brand new characteristic that additionally shows class names to the consumer, in a dropdown. In one of many 6 runs, the agent truly found that and instructed to additionally change that place to make use of the brand new performance.
| Discovered the reusable code | Went the additional mile and located the extra place the place it ought to be used |
|---|---|
| Sure | Sure |
| Sure | No |
| No | Sure |
| No | No |
| No | No |
| No | No |
I put these outcomes right into a desk for instance that in every process given to an agent, we now have a number of dimensions of high quality, of issues that we wish to “go proper”. Every agent run can “go unsuitable” in a single or a number of of those dimensions, and the extra dimensions there are, the much less possible it’s that an agent will get all the things performed the way in which we would like it.
Sunk value fallacy
I’ve been questioning – let’s say a staff makes use of background brokers for this kind of process, the forms of duties which might be type of small, and neither essential nor pressing. Haiven is an internal-facing utility, and has solely two builders assigned in the mean time, so this kind of beauty repair is definitely thought of low precedence because it takes developer capability away from extra essential issues. When an agent solely type of succeeds, however not totally – wherein conditions would a staff discard the pull request, and wherein conditions would they make investments the time to get it the final 20% there, though spending capability on this had been deprioritised? It makes me marvel in regards to the tail finish of unprioritised effort we would find yourself with.

{kind=link}